AWS Glue crawlerとAthenaを使ってS3に置いてあるCSVファイルへSQLを実行する
AWS Athenaを使ってS3に置いてあるCSVファイルへSQLを実行する機会はあるのですが、自分で環境構築をしたことがありませんでした。 また、AWS Glueは様々な機能を持っていて、Athenaとどう関係があるのかを理解できていませんでした。 そこで、Athenaの環境構築をTerraformでやってみます。
最低限下記の3つを作成する必要があります。
テーブルについては手動で作成することもできますが、Glueクローラーを使ってCSVファイルから自動で作成することもできます。 今回はGlueクローラーを使います。
Glueクローラーの作成
Glueクローラーを作成するために下記を行います。
resource "aws_glue_catalog_database" "aws_glue_catalog_database_example" {
name = "athena-example-database"
}
data "aws_s3_bucket" "hoge_test_athena_bucket" {
bucket = "hoge-test-athena"
}
data "aws_iam_role" "glue_crawler_athena_example_role" {
name = "glue_crawler_athena_example_role"
}
resource "aws_glue_crawler" "glue_crawler_athena_example" {
database_name = aws_glue_catalog_database.aws_glue_catalog_database_example.name
name = "athena-example-crawler"
role = data.aws_iam_role.glue_crawler_athena_example_role.arn
s3_target {
path = "s3://${data.aws_s3_bucket.hoge_test_athena_bucket.bucket}"
}
}
Glueクローラーを実行してテーブルの作成
今回は下記の内容でCSVファイルを用意し、hoge-test-athena bucketへ置きました。
name,amount,price,producer,country apple,10,1500,Michael,Japan
それでは先ほど作成したクローラの名前を指定して、クローラを実行します。
aws glue start-crawler --name athena-example-crawler
しばらくするとAWSコンソール > AWS Glue > Data Catalog > Databases > Tables
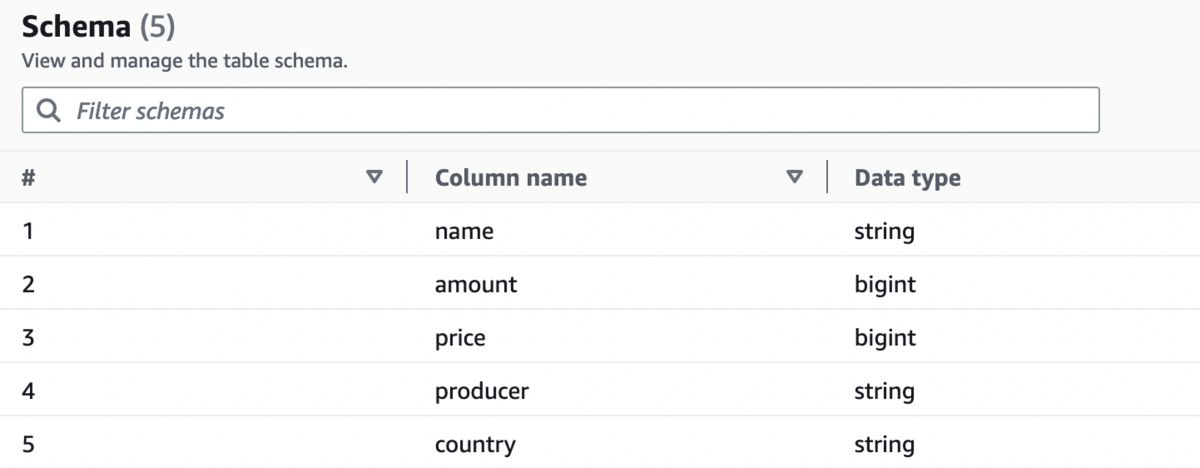
にhoge_test_athenaというテーブルが作成され、テーブルスキーマが生成されていることが確認できました。
SQLの実行
Athenaを使ってSQLを実行します。
実行するにはワークグループを指定する必要があります。
今回は下記のようにdeveloperという名前のワークグループを作成しました。
CloudWatchメトリクスは今回不要なのでfalseに、
また、result_configuration.output_locationでクエリの結果を保存するS3 bucketを指定しています。
data "aws_s3_bucket" "hoge_test_athena_result_bucket" {
bucket = "hoge-test-athena-result"
}
resource "aws_athena_workgroup" "developer" {
name = "developer"
configuration {
publish_cloudwatch_metrics_enabled = false
result_configuration {
output_location = "s3://${data.aws_s3_bucket.hoge_test_athena_result_bucket.bucket}"
}
}
}
それではクローラによって作成されたテーブルに対してSELECT文を実行してみます。 ワークグループはdeveloperを指定します。
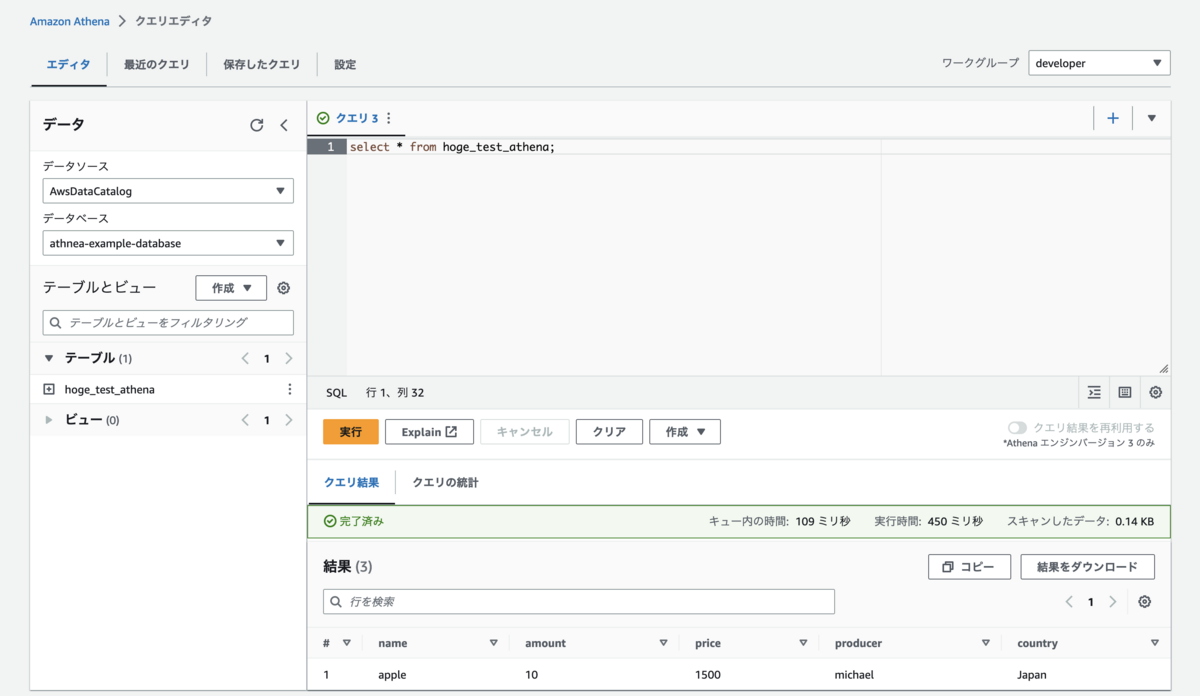
期待通りの結果が確認できました。